找回遗失的笔记
文章目录
前言
前一段时间用印象笔记的markdown功能写笔记,写到一半,印象笔记突然卡住了一下,在卡住之后,无法继续编辑,内容无法复制,远程同步和导出的内容都是上一个历史版本的内容,而上一个历史版本相较当前版本还是差了好些内容,
作为一个看过张银奎大佬写的《格蠹汇编》的程序员来说,第一个想法便是将内容从内存中dump出来。
解决
首先需要找到印象笔记的进程,查看任务管理器,这里有好多个进程。
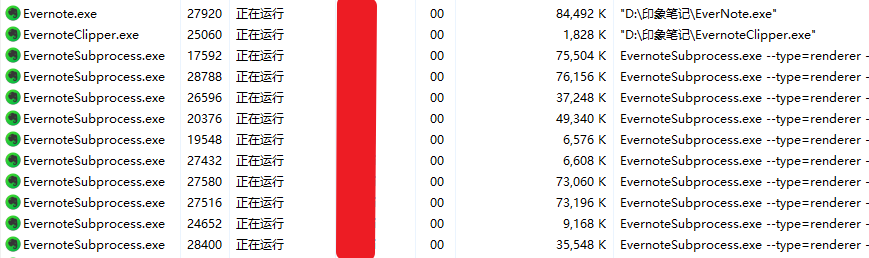
不清楚显示内容的具体对应哪个进程,这里使用spyxx,找到markdown渲染后的窗口所属的进程。
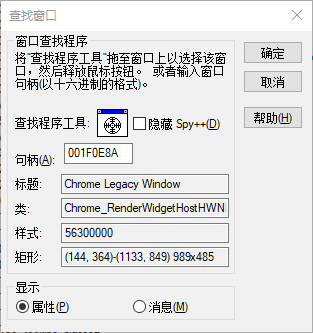
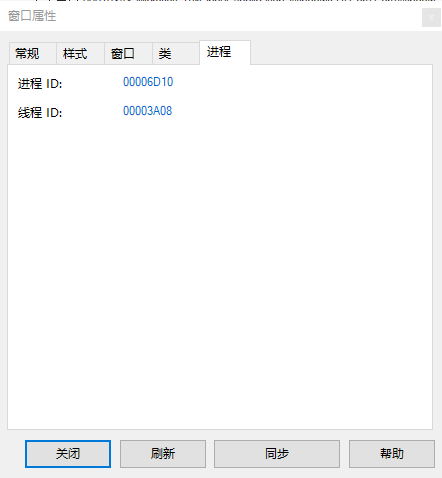
这里显示进程是0x6D10,换算成10进制是27920,也即Evernote.exe进程。
在查看Evernote.exe进程的内存数据之前,先说明下笔记的一些关键信息。
我的笔记一开始是写了开头和结尾,之后在开头的基础上开始完善内容。在出现问题的那一时刻,我笔记的起始内容是:最近需要使用,正在编辑的内容是:Protobuf协议,文章结束内容是:protocol类型的数据。而我提到的上一个历史版本中,则只保留了开头的最近需要使用和结尾的protocol类型的数据。
接下来,使用windbg附加Evernote.exe进程,使用命令s -u 0 L8000000 "最近需要使用" 在进程里面搜索,没有找到任何地址。而使用s -u 0 L8000000 "类型的数据"命令则找到了2个地址。

只找到了结尾的内容,而没有找到开头的内容,这里肯定是哪里有问题。我后面有重启进程,重新附加试了多次均没有结果。
最终我没有办法,只能先用截图+OCR的方式将中间缺失的内容给搞出来了。在把内容搞出来之后,不死心,一定要用内存dump的方式将数据给搞出来。
我后面想到印象笔记其实有多个进程,是不是spyxx没识别对,于是我便用windbg一个个附加试了下。
直到进程20376,起始、缺失以及结尾的地址均找到了,看来确实是进程不对的问题。
起始内容的地址有这些。
|
|
缺失内容的地址有这些。
|
|
文章结尾的地址有这些。
|
|
每个关键字符串搜出来的地址有多个,简单梳理一下,合理的地址有这些。
|
|
使用以下命令依次将内存写入文件。
|
|
使用编辑器打开文件txt1.txt,显示乱码,在预期之中。
加载到Python中,使用chardet库看下可能是哪个编码。
|
|
检测可信度只有25%,大概率是错的,decode了一下,果然是乱码。

后面试了下UTF8、GBK,都不对。后面注意到,每个ASCII字符后面都会跟一个0,猜测可能是UTF16,试了下,果然。

依次解码上述3个内存的数据,其中数据1和数据2都是原始的markdown数据,而数据3不对,一个合理的地址范围是:0a8beb1a -> 0a8c74ce,这个是上一个历史版本的html内容。
至此,终于通过技术手段将丢失的内容找回来了😁。
参考文章
- 《格蠹汇编》第1章。