记 pybind11 加载 torch 崩溃问题定位
文章目录
一、服务背景
线上的一个服务使用 Python 代码处理数据,处理期间会对数据做一些计算,并使用服务提供的模型、DB 等异步接口与外部做一些交互。
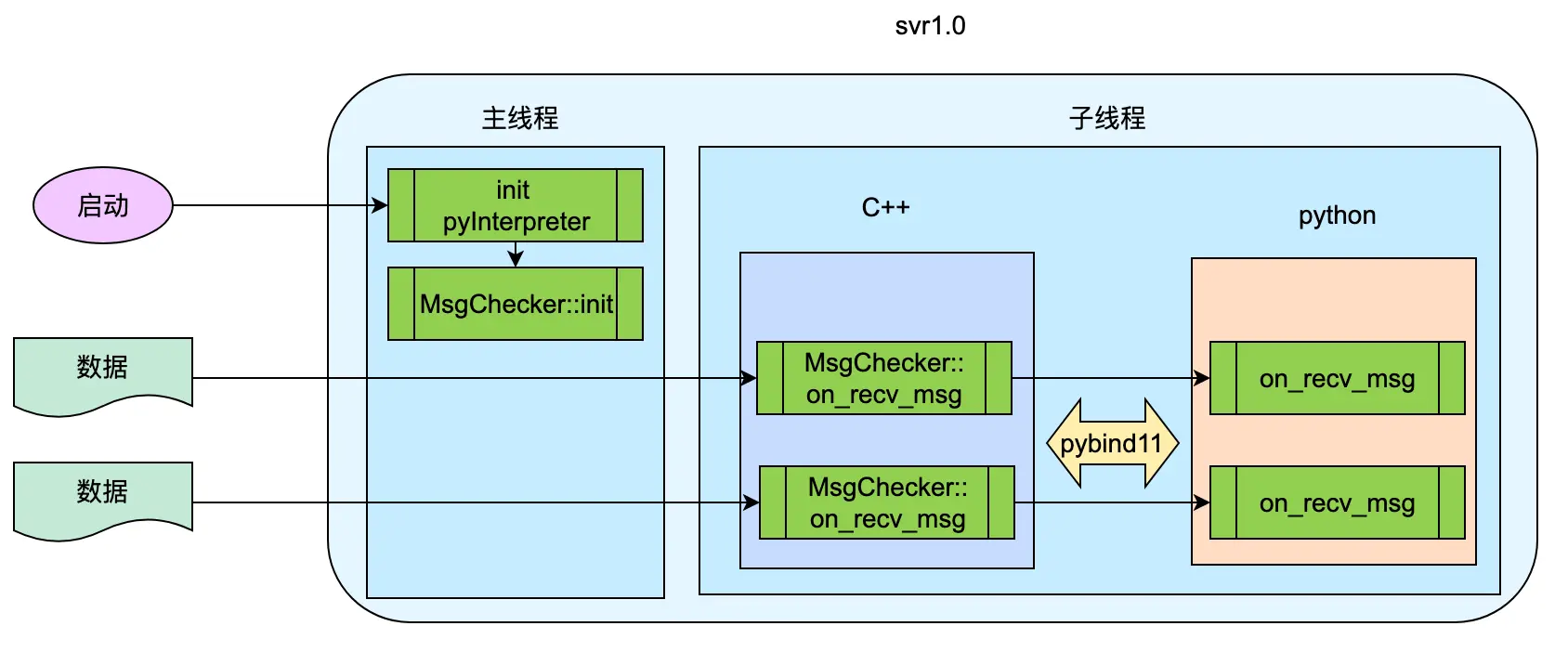
整个服务使用 C++ 开发(C++ 基于 GCC 4.8.5),使用 pybind11 嵌入 Python 解释器的方式执行 Python 代码(Python 基于 3.9.1)。服务在初始化 Python 解释器后,会创建名为 MsgChecker 的类实例并执行 init 方法初始化,之后在子线程中循环往复的调用 MsgChecker::on_recv_msg 方法将数据给到 Python 代码处理。
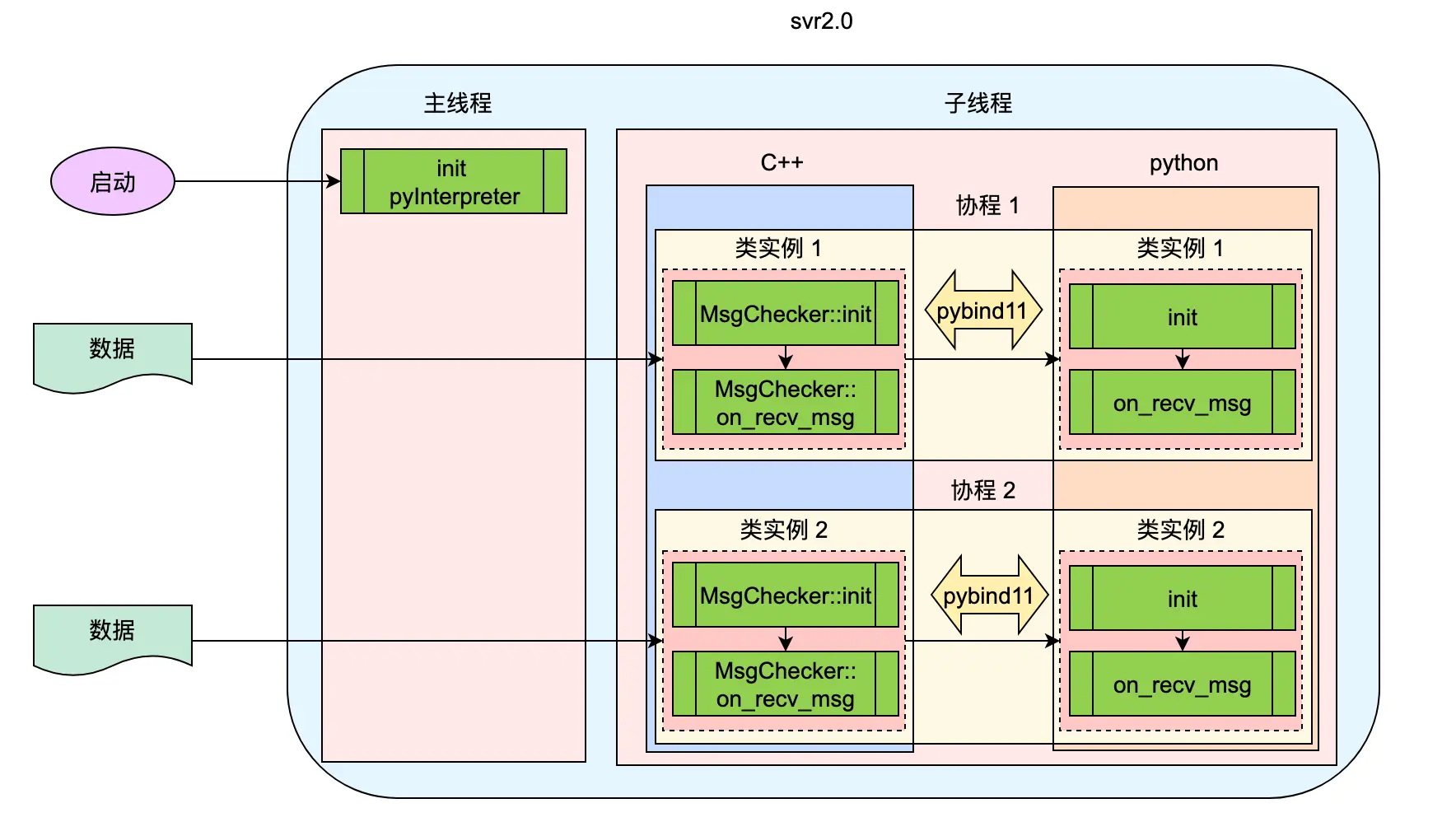
在最新版本的 svr 中(后续简称 svr2.0),引入了协程,将模型预测、DB 读写等接口由异步改为同步,简化接口的调用,降低 Python 开发者的心智负担。
二、崩溃说明
一个业务在 svr1.0 中有使用 torch 包加载模型进行模型预测,整个流程运行良好。但在升级 svr2.0 后,进程启动并在处理第 2 或第 3 个文件时必将发生崩溃。崩溃堆栈如下。
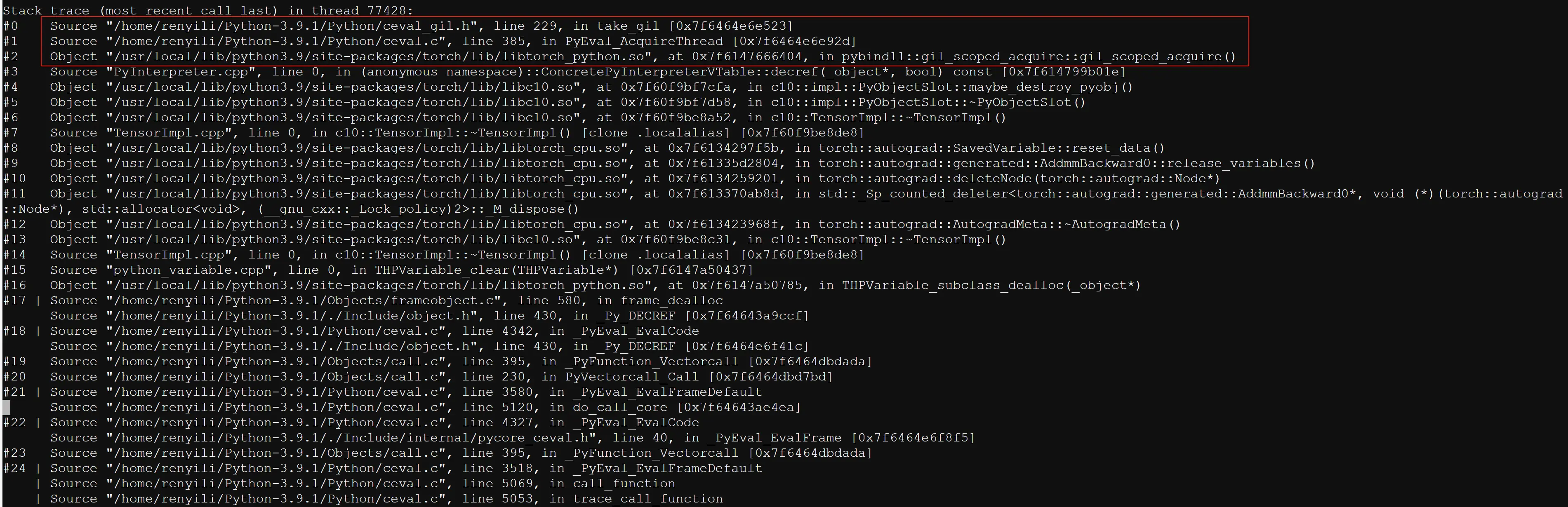
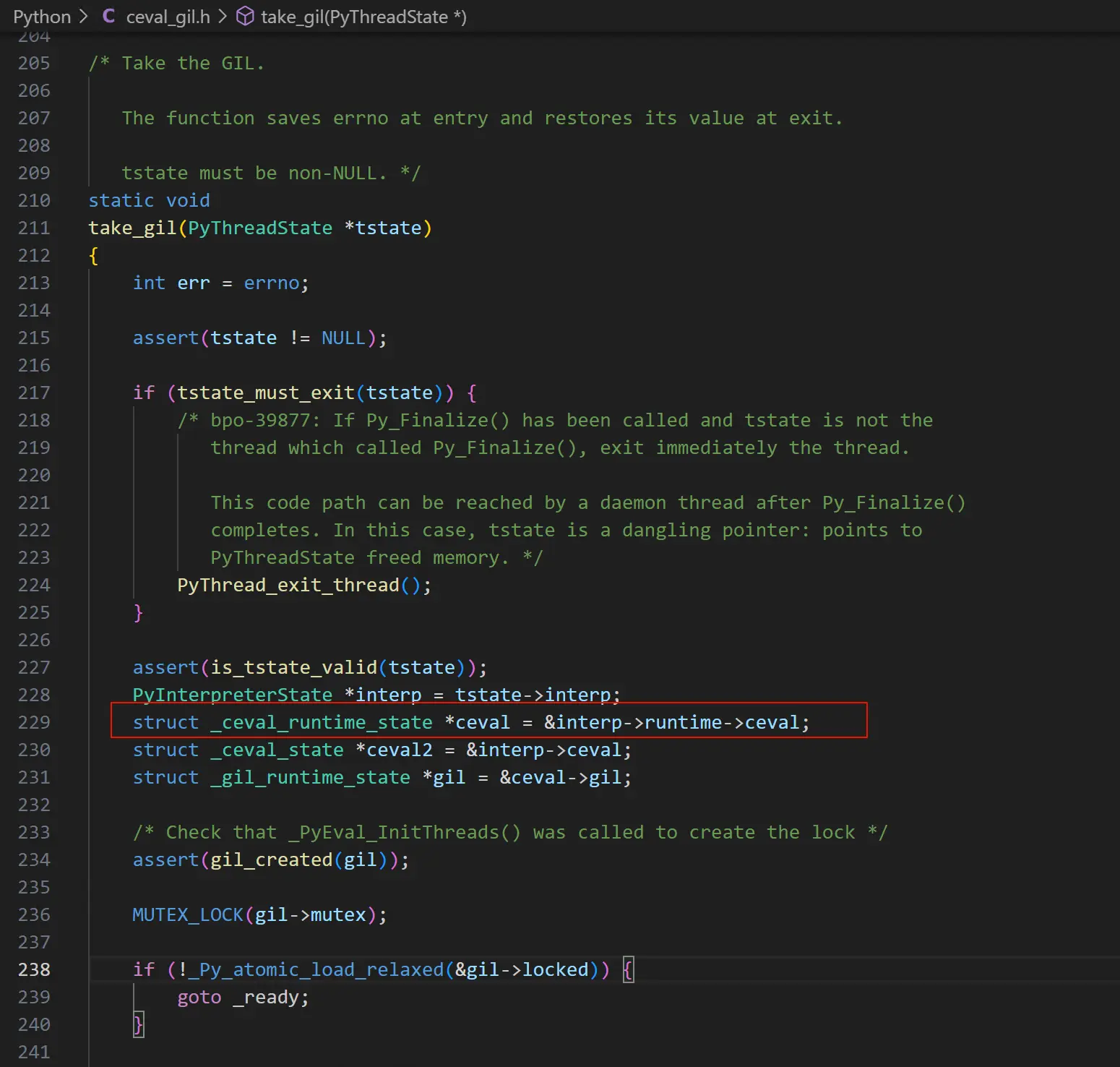
崩溃发生在 torch 模块中,其在调用 pybind11 的 gil_scoped_acquire 的函数获取 GIL 锁时触发了崩溃,崩溃点对应的 Python 代码如下。
三、定位
3.1 思路一
由于堆栈崩在 Python 代码中,且 svr1.0 并没有问题,因此我认为应该是应用层而非 Python 的问题,所以一开始没有从堆栈入手,而是聚焦于 svr2.0 与 svr1.0 之间的差异。考虑了几个点。
- 本地搭建 demo 尝试复现,本地复现后,可以更容易的修改代码进行定位测试验证。
- 服务依赖的 pybind11 库,是否是 pybind11 的 bug,升级是否可以解决?
- 是否是 torch 库的问题,升级或降低 torch 库能否解决?
- svr2.0 框架与 svr1.0 的差异是什么?可以不断地修改 svr2.0 的代码并接近 svr1.0 的流程,以确认两个版本间的哪个差异导致了该问题。
我很快在本地开发了 demo,但 demo 并未复现线上的崩溃问题。仔细考虑了其流程与 svr2.0 的差异,没有发现差异。
我又尝试了升级 pybind11 的版本,并在线上测试,问题依旧可以复现,因此可以排除 pybind11 版本的问题。
我也尝试了升级或降级 torch 库的版本,问题也依旧可以复现,也排除了 torch 库版本的问题。
既然如此,只能尝试方案 4 这个比较麻烦的方式了。
从架构来看,两者最直接的差异是,
- svr1.0 中所有对局的解析共用一个
MsgChecker类,每次给MsgChecker类的on_recv_msg方法传递不同的数据进行解析。 - svr2.0 中使用了协程,针对每个对局都会创建一个协程,每个协程中的对局都会对应一个
MsgChecker类实例,调用MsgChecker类实例的on_recv_msg方法进行对局解析。
svr2.0 中的协程是我略微修改了 pybind11 的 GIL 锁相关代码实现的,这里可能是一个问题。因此我首先将协程的逻辑全部删除,不再使用协程,但对于每个对局,依旧会创建一个 MsgChecker 类实例进行处理,这样依旧可以复现问题。至此可以排除协程实现的问题。
接下来,就是不断的修改删除代码并测试。由于崩溃只能在线上复现,所以这个过程花费了不少时间。
但功夫不负有心人,经过不断的测试,发现将 torch 放在主线程中进行加载初始化时,整个程序就不会崩溃。
svr1.0 中只初始化一次,且初始化逻辑是在主线程中,当收到文件处理时,会在子线程中调用 on_recv_msg 函数进行处理。而 svr2.0 中,在主线程中不做任何初始化逻辑,当收到文件处理时,直接在子线程中创建 MsgChecker 类加载初始化 torch,同时对文件进行处理。
虽然定位出了差异点,接下来的问题是,为什么在主线程中加载初始化 torch 就没问题,而在子线程中初始化 torch 就有问题?
3.2 思路二
网上查了些资料,torch 并没有不能重复加载、不能在子线程中加载之类的问题,继续修改代码测试也没有意义。
无奈只能尝试从堆栈入手,从崩溃点一层层的往上回溯,确认导致崩溃的原因。
从堆栈中发现,在子线程中,开始调用 Python 函数的 tstate 数据(PyThreadState)的指针与最终触发崩溃时的 tstate 的指针不同,这不符合常理。整个逻辑处于一个线程,且在同一个调用链上,中间不应该触发 tstate 的删除释放。
看起来直接原因定位到了,一定是哪里内存错误或是逻辑问题导致 tstate 数据异常了。接下来的问题就是去定位为什么 tstate 的指针发生了变化。
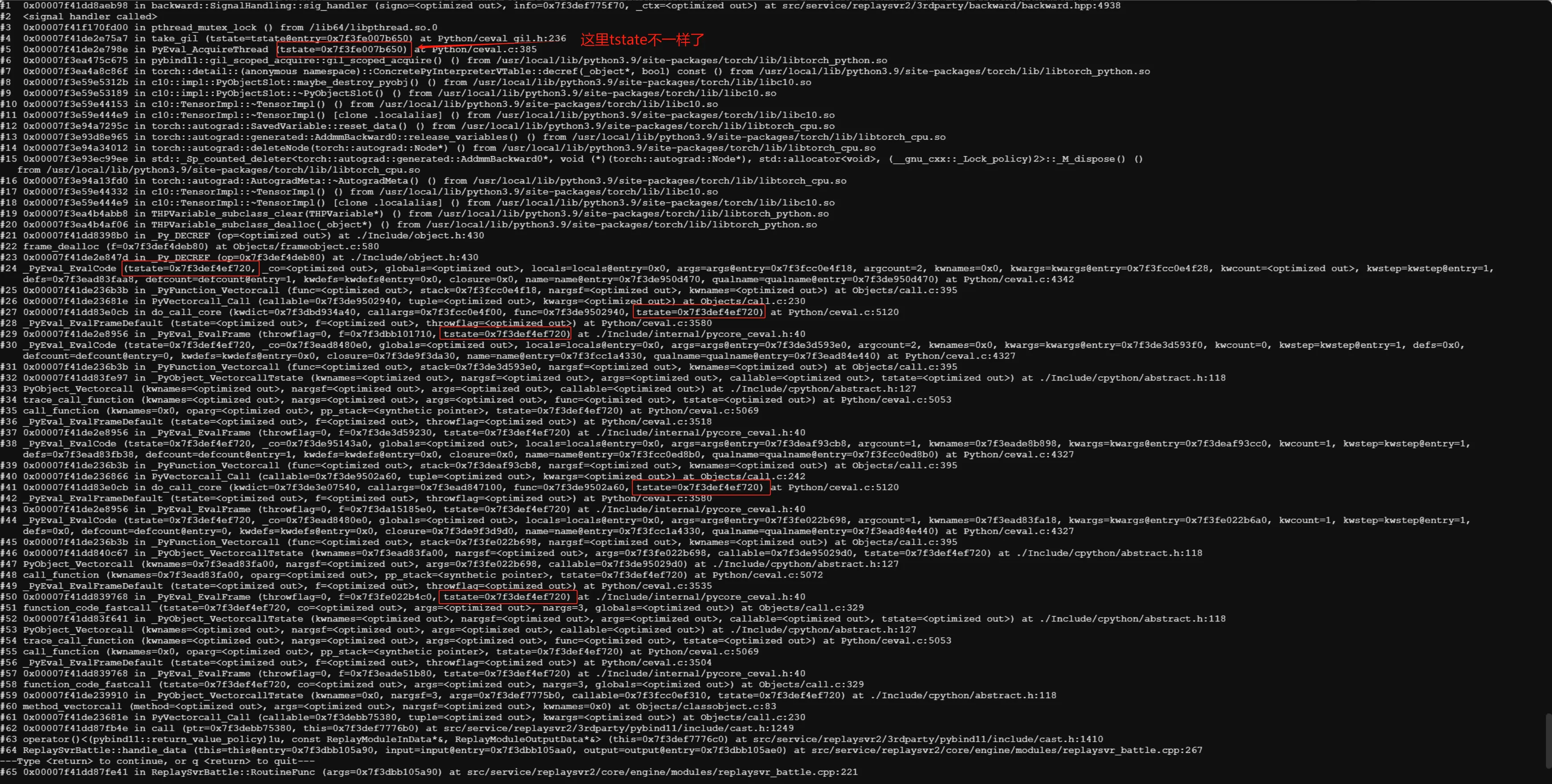
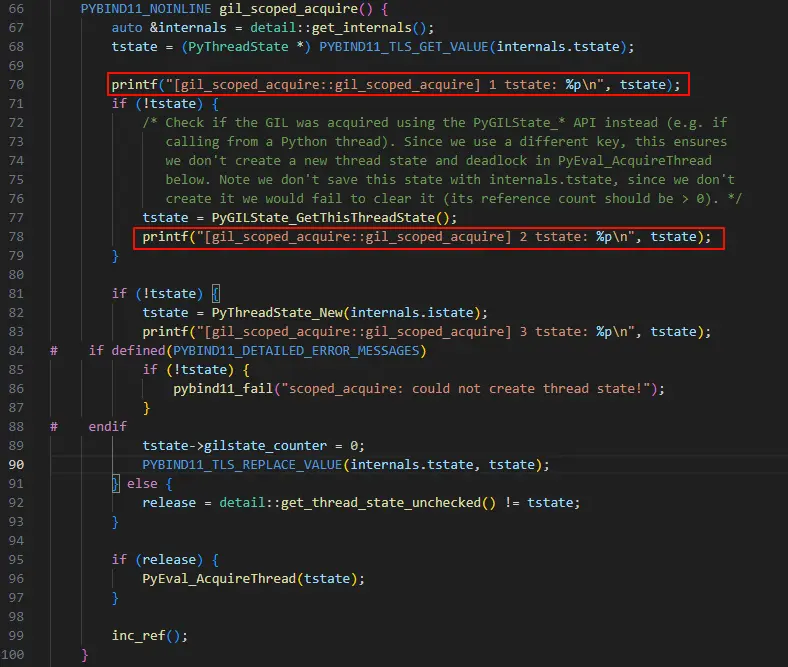
从调用栈来看,在 tstate 发生变化时,torch 调用了 pybind11 的 gil_scoped_acquire 方法用于获取 GIL 锁,gil_scoped_acquire 方法的代码如下。
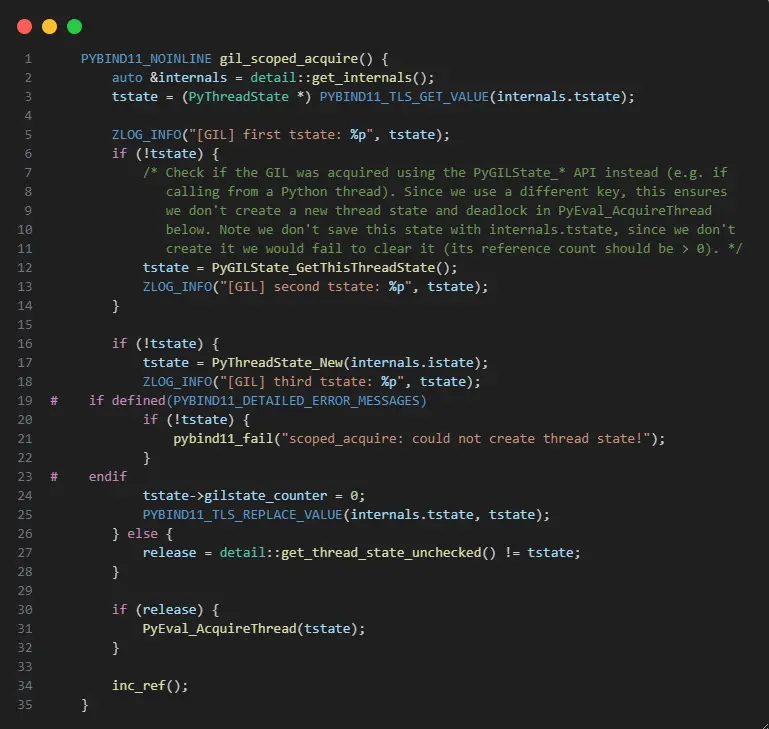
在 Python 的 C/C++ 扩展模块中要执行 Python 代码必须要获取 GIL 锁,pybind11 库提供了 gil_scoped_acquire 类允许我们获取 GIL 锁,gil_scoped_acquire 类基于 RAII 机制,在离开作用域后,将会自动释放 GIL 锁。
从代码逻辑看,获取 GIL 锁的前提是要先获取当前线程的 PyThreadState 线程状态数据。
PyThreadState是 Python 解释器内部用于管理线程状态的核心数据结构,主要有以下作用:1. 每个 Python 线程对应一个独立的
PyThreadState对象2. 保存线程特有的解释器状态(如当前帧、异常状态等)
3. 是 Python 实现 GIL(全局解释器锁)机制的基础
从 gil_scoped_acquire 的代码中可以看到尝试了 3 种方式获取 PyThreadState 数据。
- 通过内部维护的
tstatekey 尝试从 TLS 数据中获取tstate数据。get_internals方法后面再做分析。这种方式获取的tstate数据由 pybind11 内部进行维护的。 - 尝试调用
PyGILState_GetThisThreadState获取tstate数据,这种获取的tstate数据由 Python 维护。 - 如果以上两种方式都获取不到
tstate数据,那么就会尝试创建新的tstate数据。
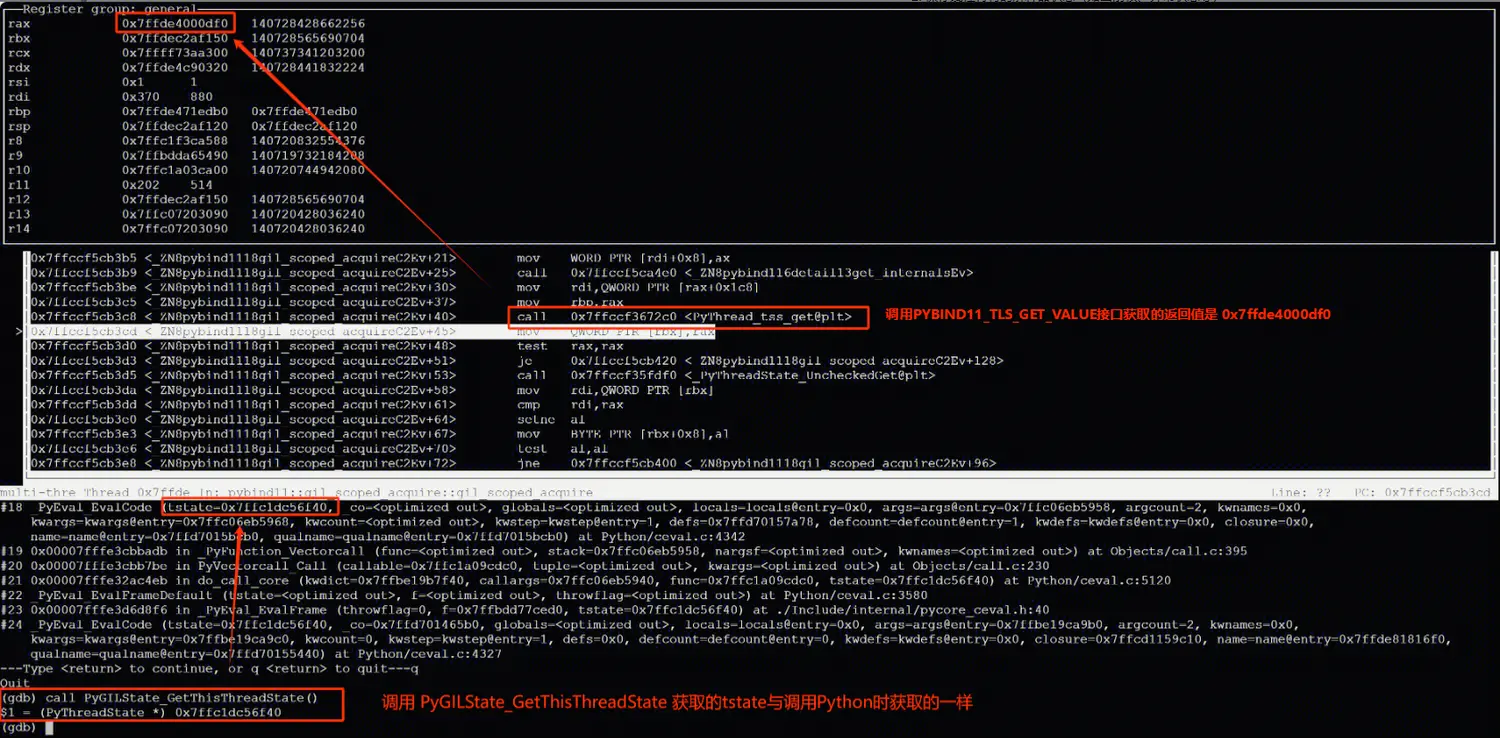
在线上崩溃点调试时可以看到,调用 PyGILState_GetThisThreadState 获取的 tstate 指针与 svr 调用 Python 时的 tstate 指针相同,而通过 get_internals 方法获取到的 internals 数据,以及以 internals.tstate 作为 key 获取的 tstate 指针却是另一个值。
get_internals 方法的代码如下,在 pybind11 内部维护一个静态的 internals 数据指针,这个 internals 数据中存储有 pybind11 内部的状态数据。
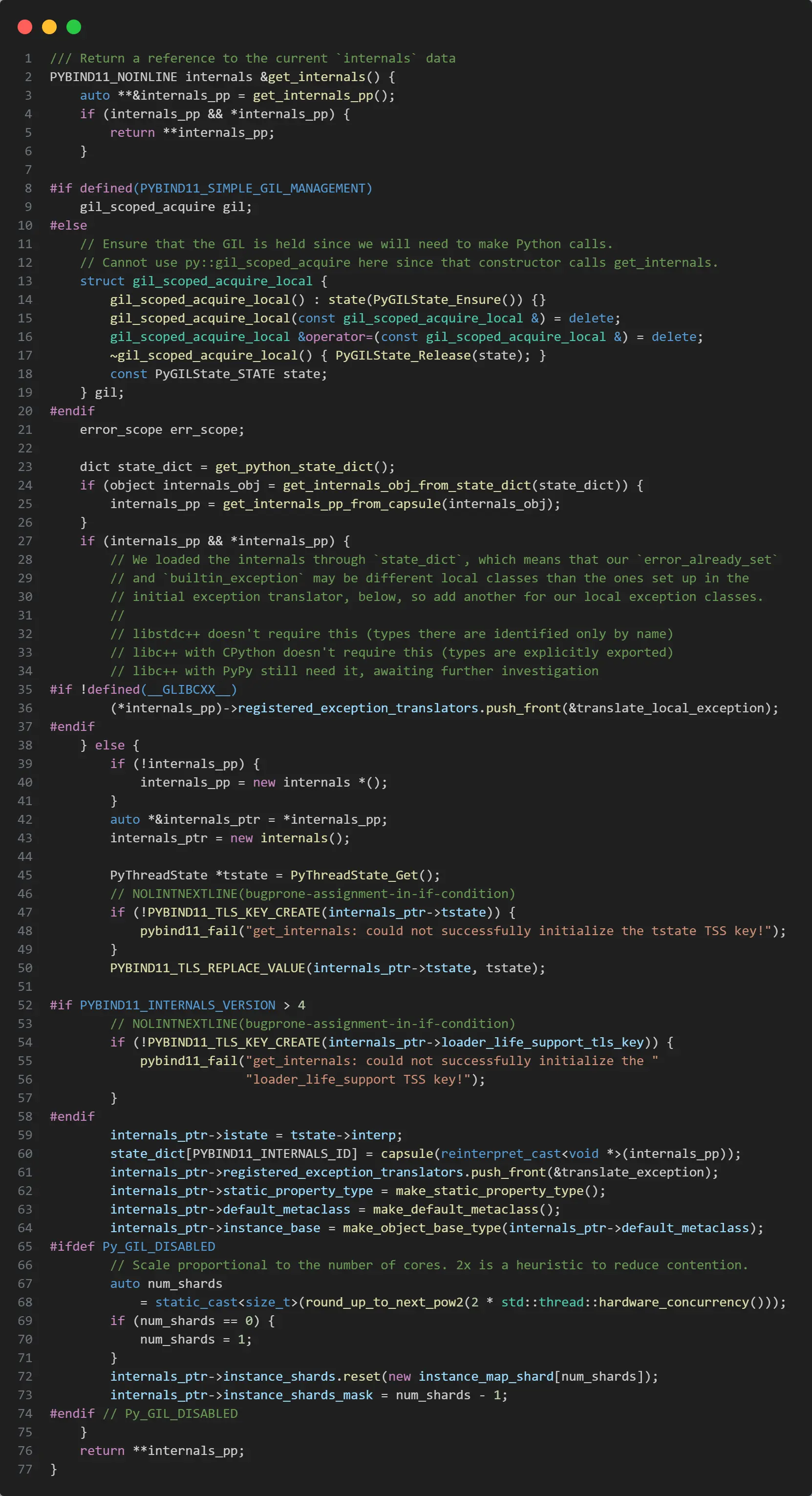
其中依赖的部分函数代码如下。

稍显复杂,大体逻辑上是这样的。
- 尝试获取静态的
internals数据指针。 - 如果获取不到,就会尝试从 Python 状态字典(解释器全局唯一)中通过宏
PYBIND11_INTERNALS_ID作为 key 获取internals数据。 - 如果还获取不到,那么就会尝试创建
internals数据指针,同时将当前 Python 线程的tstate数据存储到 TLS 中,并将 TLS 的 key 存储到internals.tstate变量中。
其中的 PYBIND11_INTERNALS_ID 宏是由另外几个宏拼起来字符串,其中的 PYBIND11_PLATFORM_ABI_ID 和编译器的版本有关。

分别验证下 svr 和 torch 中的 PYBIND11_INTERNALS_ID 宏值,两者并不相同。

捋一下逻辑,
- svr 先调用 pybind11,并创建
internals数据。创建后,就会将internals放在PYBIND11_INTERNALS_ID(__pybind11_internals_v4_gcc_libstdcpp_cxxabi1002__) 作为 key 的 Python 状态字典中。 - 当后面调用 torch 时,torch 中的 pybind11 通过步骤 1 肯定拿不到 svr 中的静态
internals指针,因此他会尝试通过他的PYBIND11_INTERNALS_ID(__pybind11_internals_v4_gcc_libstdcpp_cxxabi1011__) 宏从 Python 状态字典中获取internals数据指针。 - 由于 torch 的宏值和 svr 的不一样,因此 torch 就会创建他自己的
internals数据。
由于 svr 和 torch 的 internals 数据不一致,那么是否 internals.tstate 数据也不相同?进而导致获取的 tstate 数据也不相同?
在 github 上查找了一些相关的 issue,其中在 83101 这个 issue 中,提到 pybind11 有另外一种获取 GIL 锁的方式。
从最新的 gil.h 代码中确实有看到相关的逻辑(在使用 PYBIND11_SIMPLE_GIL_MANAGEMENT 宏的情况下),但如果要用这部分代码,就要求同一个解析器中的所有 C/C++ 扩展模块都使用该方式重新编译,就我这个问题来说,需要添加 PYBIND11_SIMPLE_GIL_MANAGEMENT 宏,重新编译 svr 和 torch。
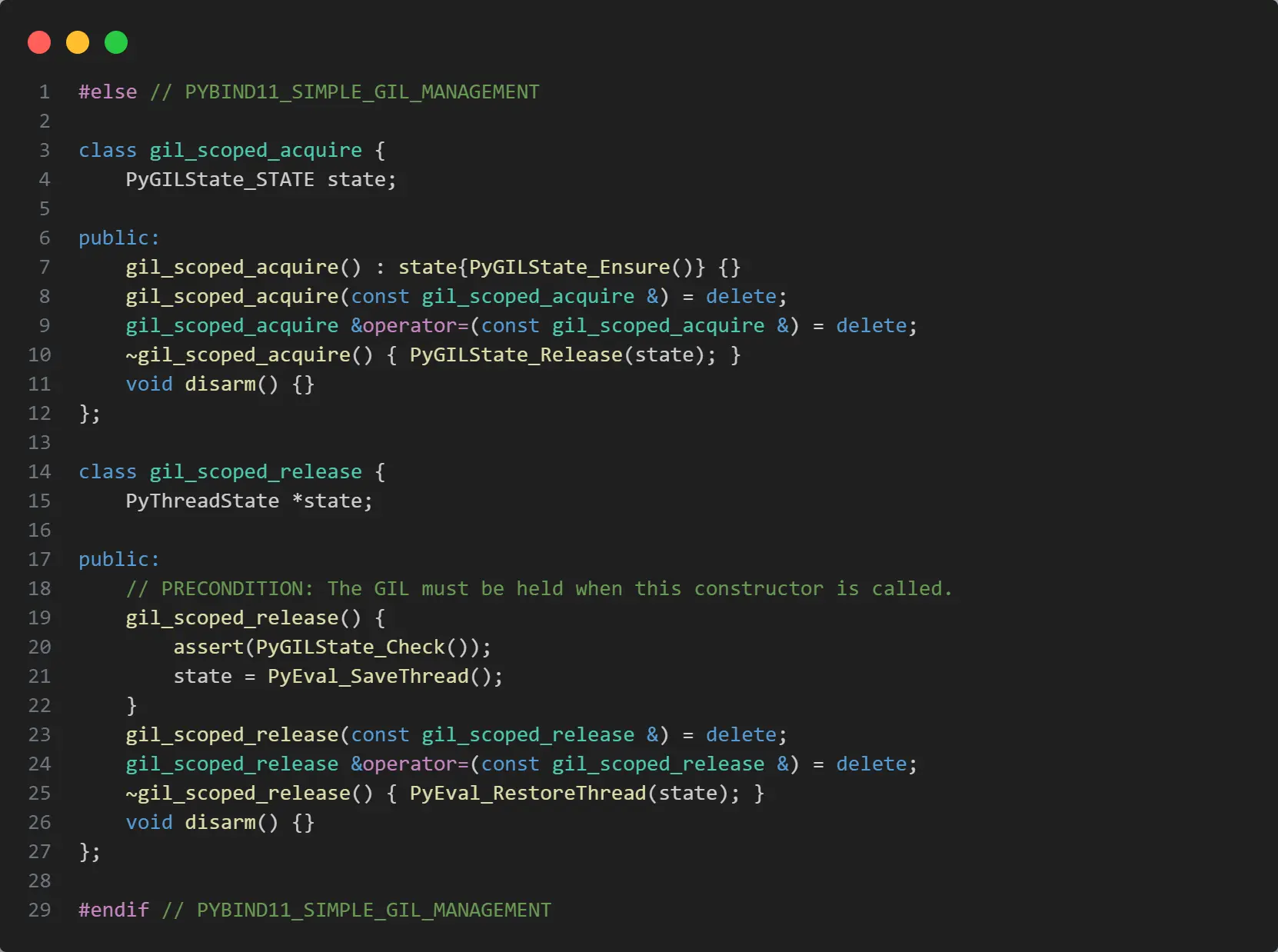
我确实花了一番精力编译了 torch,但编译后发现编译环境的 LIBCXX、LIBC 版本都要比线上环境的高,压根跑不起来。
而如果尝试用低版本的环境去编译 torch,则根本不符合 torch 需要 C++17 编译器的需求。
另一个思路是升级 svr 的编译器,确保 svr 和 torch 的 PYBIND11_INTERNALS_ID 宏值一致,进而保证他们使用同一个 internals 数据。
在将 svr2.0 使用 9.2 版本的 GCC 编译并发布线上后,确实没有出现崩溃问题。
似乎问题解决了~
3.3 两个旧问题
实际上还有两个问题没有确认清楚。
- 本地 demo 使用的 gcc 版本与线上一致,且也加载了 torch,为什么在本地没有复现崩溃?
- 为什么同样使用 gcc 4.8.5 版本编译的 svr1.0 没有问题?
我决定先解决第 1 个问题。
之前的 demo 中加载了 torch 库,现在已经确定崩溃和 torch 中的 pybind11 有关系,为了聚焦问题并方便测试,我又新实现了一个 C++ 扩展模块,同时强制指定 __GXX_ABI_VERSION 宏值为 1001,让其生成的 PYBIND11_INTERNALS_ID 宏值与 svr 的不同,用于模拟 torch。
整个程序包括 5 部分,完整的代码见 GIT仓库。
- loader 程序,主程序,负责加载模拟的 svr.so 文件。
- svr1.so 模块,用于模拟 svr1.0 版本。
- svr2.so 模块,用于模拟 svr2.0 版本。
- logic.py 代码,模拟线上的策略代码。
- mytorch.so 模块,模拟线上的 torch 模块。
程序使用 cmake 构建,使用 4.8.5 GCC 编译器,同时依赖 Python 3.9.1 版本(可通过 conda 安装)。编译完毕后,在 build 目录下运行命令 ./loader ./svr1.so 和命令 ./loader ./svr2.so 分别模拟 1.0、2.0 两个版本的执行。
在 CMake 配置中,我通过强制定义 mytorch 的 __GXX_ABI_VERSION 宏值为 1001,确保其 internals 数据与 svr 的数据不一致。

同时我在 pybind11 的 gil.h、internals.h 中增加了相关日志,比对线上与线下的区别。
线上 svr 的日志。

而本地运行的日志如下。
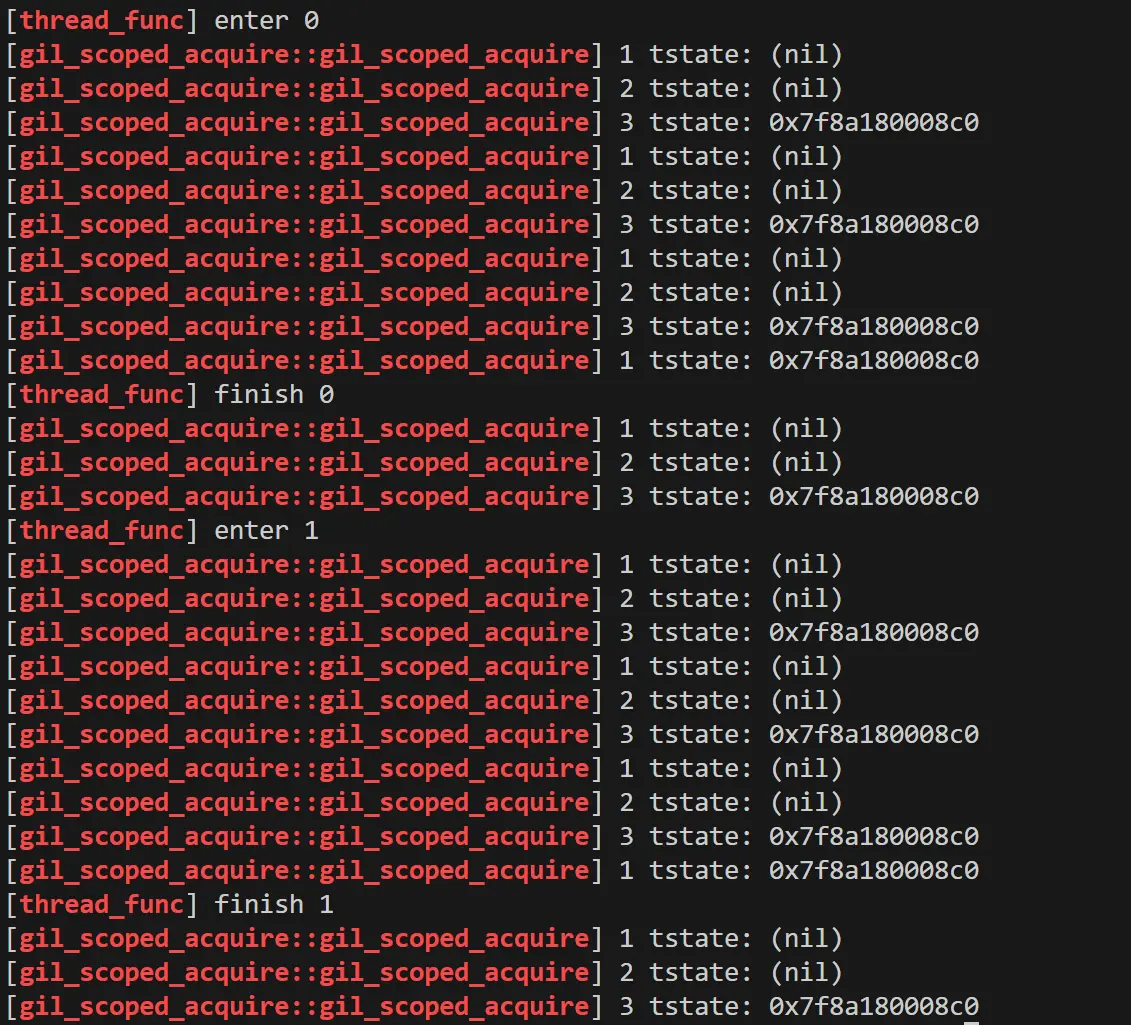
可以看到,在 svr 中解析文件的过程中,tstate 的指针一直在变,而在本地 demo 中 tstate 的指针一直是同一个。
看到这里大概明白原因了,demo 逻辑比较简单,且内存充裕,在内存释放后并未被系统回收,而是缓存了起来,当又新申请时,由于大小相同,所以又把这块内存给了出来。
由于指针相同,因此变相的让 svr 模块与 torch 模块的 tstate 数据进行了同步。
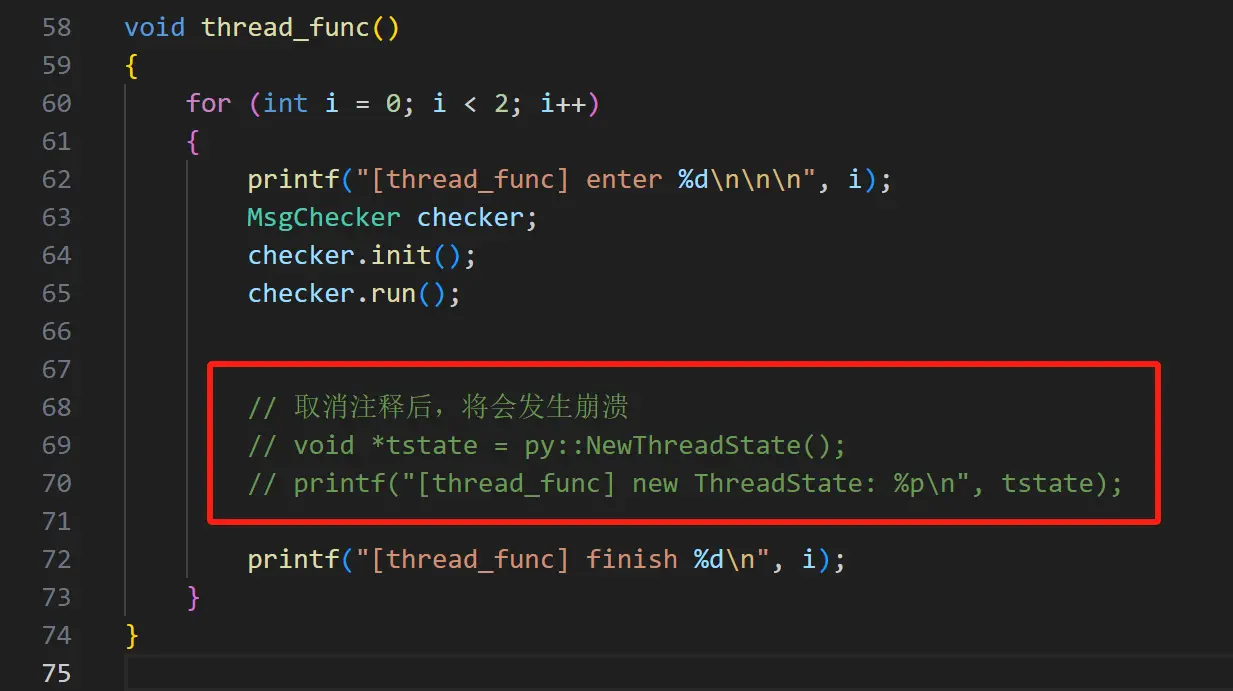
要验证这个问题也比较简单,在本地 demo 解析完第一个文件后,手动申请一段与 PyThreadState 大小一致的内存,这样就把地址占住了。在解析第二个文件的时候,地址就只能发生变化了。
svr2.cpp 中有一段注释,取消注释后,将会申请一个空的 tstate 变量,将之前释放的指针占住。
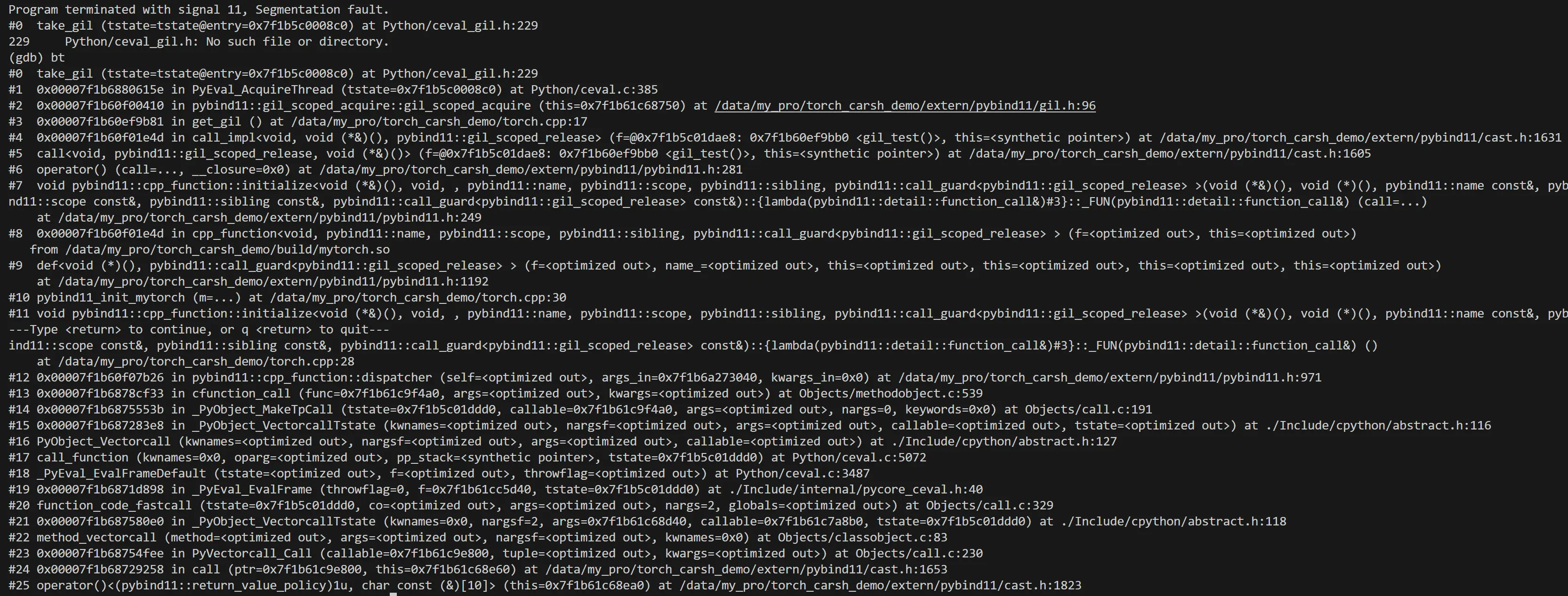
再次编译执行,果然程序挂掉了,最终的崩溃点和线上基本一样😅。
继续来看第 2 个问题,同样是 4.8.5 版本的编译器,为什么在 svr1.0 中没有问题?
线上 svr1.0 的版本对应本地 svr1.cpp 中的代码。它与 svr2.cpp 的主要区别在于它的 torch 的初始化逻辑在主线程中只执行一次,而不是在每次解析文件时都初始化一次。
再次比对 svr1.so 和 svr2.so 的逻辑和相关的日志输出,区别如下。
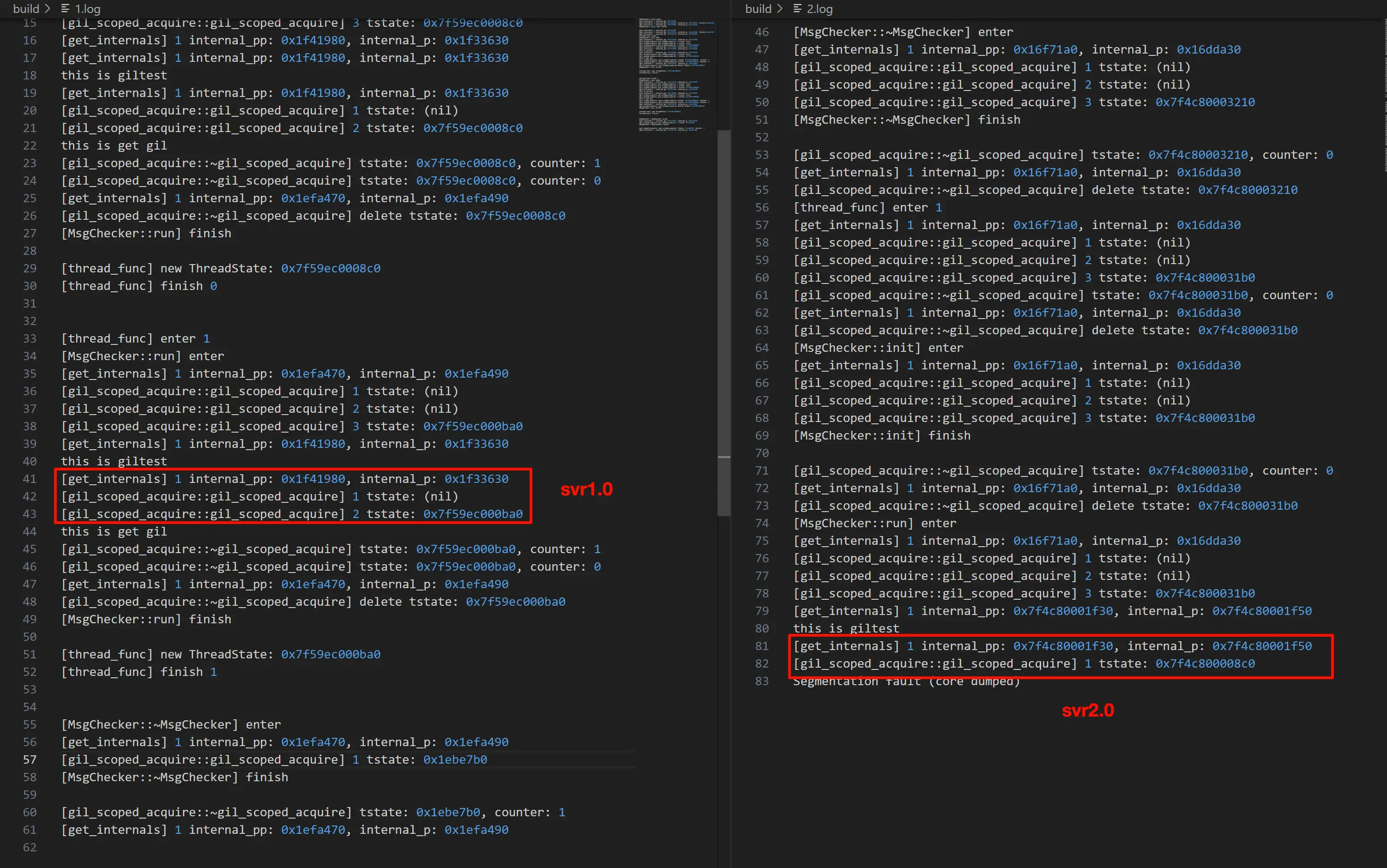
崩溃前,在 svr1.0 中是通过 PyGILState_GetThisThreadState 获取到了 tstate 数据,而在 svr2.0 中,则是以 internals.tstate 作为 key 从 TLS 中获取到了 tstate 数据。
仔细分析 svr2.0 的日志。
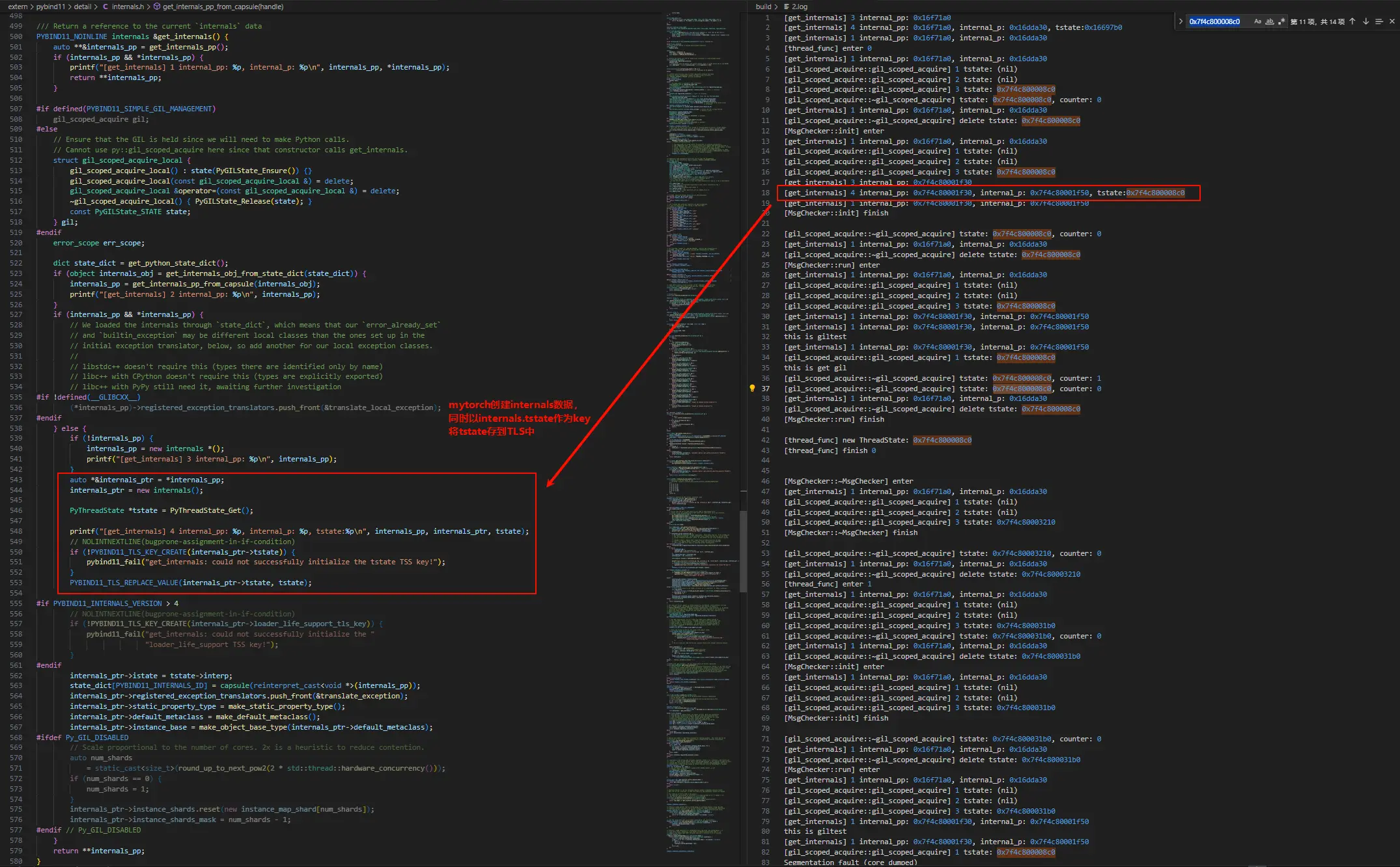
看到这里原因大概清楚了,这与 torch 初始化时所在的线程有关,再重新捋一遍逻辑。
假设 torch 在主线中加载并初始化(svr1.0 的逻辑)。
- 主线程中。
- 首先 svr 创建
internals数据,并将当前线程的tstate数据存储在 TLS 中,TLS 的 key 保存internals数据中。 - 之后初始化 torch,torch 同样会创建
internals数据(因为PYBIND11_INTERNALS_ID宏不同),并将tstate保存在 TLS 中,TLS 的 key 与 svr 的不同,它的 key 也保存到它的internals数据中。
- 首先 svr 创建
- 子线程中。
- svr 执行 Python 代码,获取 GIL 锁,此时
internals数据已经创建,但由于在子线程,因此它无法通过internals.tstate作为 key 从 TLS 中获取当前线程的tstate数据。当前线程也没有tstate数据,因此会执行到创建新tstate的逻辑创建新的tstate数据。 - 在进入 Python,并进入 torch 逻辑后,torch 也需要获取 GIL 锁,此时它也能直接拿到
internals数据,但是也无法通过internals数据中的 key 拿到tstate值,此时就会调用 PyGILState_GetThisThreadState,该接口会自动获取当前线程的tstate数据,完全没有问题。 - 解析完一个文件,整个逻辑没有任何问题。
- 在开始解析第二个文件时,先前的
tstate数据已经释放,svr 调用gil_scoped_acquire时将再次创建新的tstate值。 - 再次进入 Python,并进入 torch 逻辑后,torch 此时将直接拿到
internals数据,但还是无法通过internels.tstate作为 key 获取到当前线程的tstate值(只有在创建internals数据的时候,才会将tstate存储到 TLS 中,并将 key 存储到internals中),因此会再次通过PyGILState_GetThisThreadState获取到当前线程的tstate数据,这个tstate数据是对的,因此没有问题。
- svr 执行 Python 代码,获取 GIL 锁,此时
假如 torch 逻辑是在子线程中是加载并初始化(svr2.0 的逻辑)。
- 主线程中。
- svr 初始化并创建了
internals数据。并将主线程的tstate存储在 TLS 中,其中的 key 存储在的internals数据中。
- svr 初始化并创建了
- 子线程。
- svr 执行 Python 代码,调用
gil_scoped_acquire获取 GIL 锁,此时internals数据已经创建,但无法通过其中的 key 获取当前线程的tstate数据,此时 svr 会创建新的tstate数据。 - 进入 Python 初始化 torch 逻辑,torch 逻辑此时还没有
internals数据,需要创建。基于get_internals的逻辑可以看到,在创建成功后,他会将当前线程的tstate数据存储到 TLS 中,并将 key 存储到internals数据中。 - 解析第一个文件,整个逻辑没有任何问题。
- 在开始解析第二个文件时,先前的
tstate数据已经释放(引用计数为 0),svr 在调用gil_scoped_acquire时会创建新的tstate数据。并进入到 Python 逻辑中。 - 但到 torch 逻辑获取 GIL 锁时,检查发现
internals数据存在,并将 internals.tstate 作为 key 获取到了当前线程的tstate数据。但问题就在这里,它获取的tstate数据实际上是第一次解析时 svr 创建的,在第二次这里已经失效了。失效原因是之前的tstate数据是 svr 调用gil_scoped_acquire时创建的,在gil_scoped_acquire析构时因为引用计数为 0 已经删除了。
- svr 执行 Python 代码,调用
本质还是两个 pybind11 模块内部维护的状态不一致的问题。
四、解法
既然明白了原因,那么解法也就有了。
- 升级 svr2.0 的编译器版本,确保它的
PYBIND11_INTERNALS_ID值与 torch 一致。 - 使用
PYBIND11_SIMPLE_GIL_MANAGEMENT宏重新编译 svr 和 torch。 - svr2.0 在子线程中初始化 Python 解释器,不在程序主线程中初始化 Python 解释器。
- svr2.0 增加一个主线程初始化的逻辑,让 torch 在主线程中初始化。
- 不再使用嵌入 Python 解释器的方法执行业务 Python 代码,换用 grpc-python 此类原生 Python 语言的框架。
第 1 个解法不太好,万一后续 torch 升级编译器而不自知,可能再次触发这个崩溃,隐患比较大。
第 2 个解法较为麻烦,若业务对最新 torch 版本有需求,需要配合重新编译构建 torch。
第 3、4 两个解法比较来看,正常来说,3 解决的要更彻底一些,本来框架主线程中也不需要执行 Python,直接在子线程中初始化 Python 也就彻底规避了 tstate 数据不一致的问题。但是,由于 svr2.0 中还基于 tstate 实现了基于 libco 协程的 Python 函数切换,因此方案 3 实际不行,只能先借助方案 4 规避。
第 5 个解法可作为长期方案,当前框架使用嵌入 Python 的方式执行 Python 代码在各方面都存在一些局限(不便开多进程等),后续更换为 grpc-python 框架理论上在兼容性等各个方面都会更好一些。