前言
我之前为了申请便宜的流量卡,于是注册成了流量卡的代理商,后面闲着无事就搭建了一个网站用来展示流量卡的申请信息。如果有人通过网站申请流量卡并成功激活,那么我就能获取到相应的提成。
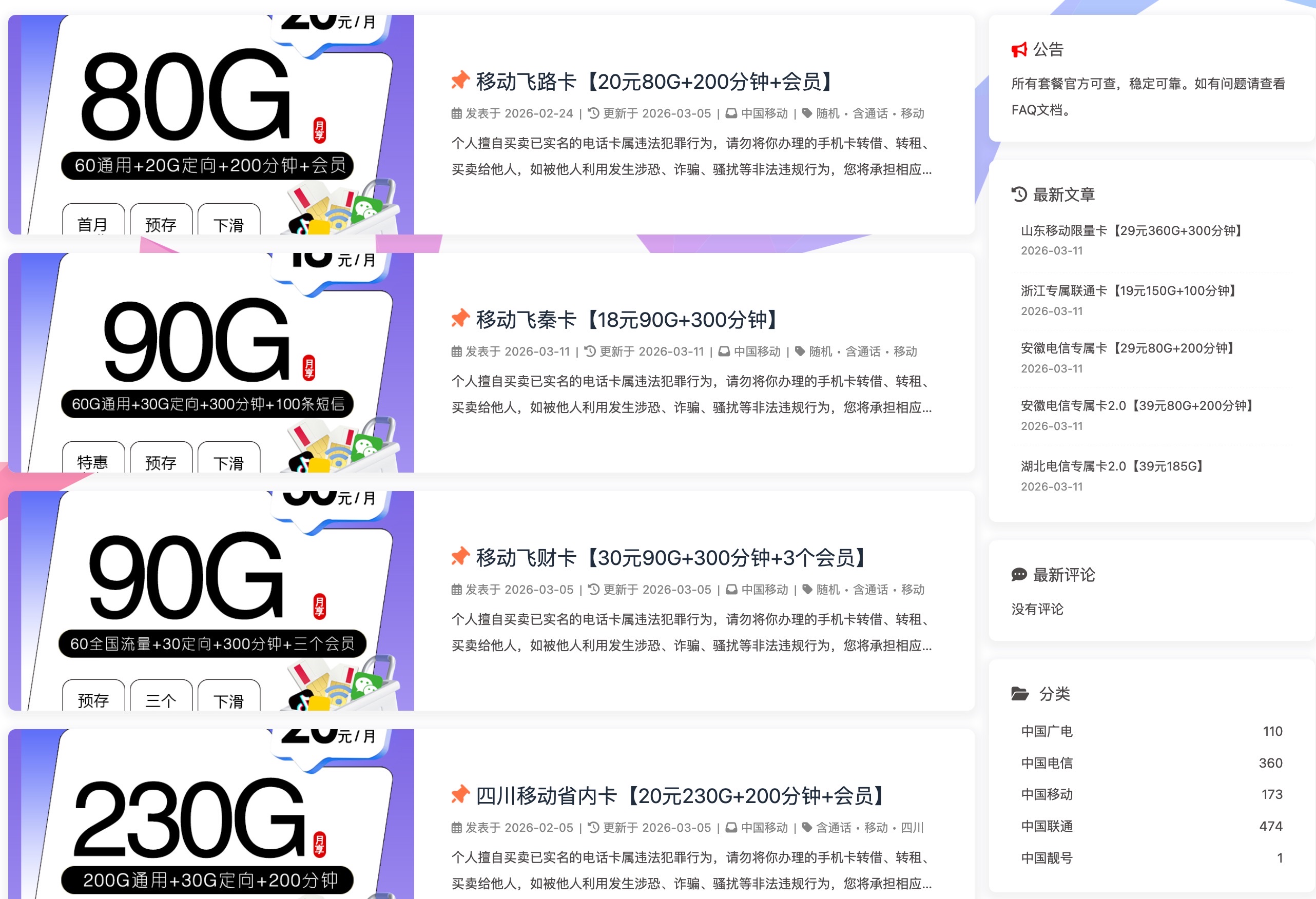
由于未做任何运营宣传,全靠搜索引擎搜索的流量,因此实际申请的人也不多。但还是偶尔会有人询问一些问题,一开始我把微信号放在了申请页面,但询问的大部分问题在套餐页面都有说明,时间长了,我也懒得回答处理,一切随缘了。
最近刚好在学习 AI Agent 相关的知识,想实践一番,刚好想到了这个场景,于是我决定实现一个客服 Agent 尝试解决下这个问题。
客服方案
为了引入客服,首先要考虑的是客服以什么样的形式与用户沟通?
我一开始的想法和之前类似,最好可以提供一个微信的二维码,用户添加好友后,由 AI 使用微信与用户进行沟通。但微信至今没有开放的接口,其他奇技淫巧也不稳定,所以直接放弃了这种方案。
后来咨询了 GPT,提供了几种方案。
- QQ 机器人。QQ 开放平台提供相应的 API,可以接入大模型进行自动回复。
- 企业微信。也有专门的客服 API 和会话接口。
- 飞书。同样提供机器人、客服功能。
- 自建网页聊天插件。
但在详细了解后,前 3 种方案都不是很合适。
QQ 机器人分为群机器人和频道机器人。如果群机器人需要让用户加群后才能沟通,且 QQ 对群机器人管控比较严格,容易被封。而 QQ 频道机器人也需要用户加入相应的频道。整体流程没那么顺畅。放弃。
企业微信可以让用户通过微信添加好友,并提供客服功能。但需要企业认证,个人用户使用受限。放弃。
飞书功能很强大,提供了丰富的接口,但用户相对微信、QQ 来说太少,大部分用户可能都没听说过。放弃。
看起来可行的办法只有自建网页聊天插件了,但这种方案我也有顾虑,提供网页聊天插件意味着我需要提供后台接口,但这也就意味着接口可能被打。
当初建这个网站时,为了减少网站被攻击的可能性,我专门采用静态网站部署的形式。后台会有一个程序定时的获取源头代理商的号卡套餐信息,并处理成 markdown 文本,再用 Hexo 这个静态网站生成工具渲染生成整个网站。由于整个网站都是静态的,被攻击的可能性大大降低。
若增加了网页聊天插件,那么这个初衷就被打破了。
我又问了 GPT 是否有现成的可集成到网页上的客服服务,显然是有的,但了解后也都需要付费后才能解锁相关的功能。无奈之下,还是只能自己实现了。
考虑了两种网页聊天插件的形态。
- 在网站右下角增加一个客服按钮,用户点击后,直接弹出来聊天框,这样用户就可以与 AI 客服进行对话了。
- 我还提供了只有聊天框的页面,当用户通过二维码联系客服时,可以自动的跳转到这个页面,进而与 AI 客服进行沟通。
形态定了,接下来的核心就是后台的 AI Agent 了。
Agent 效果
客服 Agent 的实现有很多现成的方案,例如通过 Dify、Coze 等平台,或是借助开源的 LangChain 等框架。
但这些方案都被我否了,我打算借助 AI 完全从零实现一个客服 Agent,这么做有两个原因。
- 我希望借助这个客服 Agent 一窥 Agent 的实现原理。
- 客服需要提供订单查询等功能,而这个要依赖我后台程序的登录用户态,因此整个客服功能与我的后台程序整合在一起是最好的。
按过去的经验,客服 Agent 至少要能够应对以下 5 个场景。
- 当用户查询订单信息时,可以自行查询订单接口并把订单信息告诉用户。
- 当用户想让推荐一些满足指定要求(月租多少、归属地、运营商等)的流量卡时,能够正确的推荐符合这些要求的套餐。
- 当用户想了解某款流量卡套餐的详细内容时,能够基于对应套餐的文档说明进行答复。
- 一般性流量卡套餐常识的应答,例如如何激活、注销流量卡等问题。
- 除了流量卡相关的问题外,其他问题一律回答不知道。
在我将相应的要求给到 AI 后,AI 便开始帮我实现相应的代码了。而我则负责验收功能,同时并了解这个 Agent 的实现原理。
最终的效果如下。
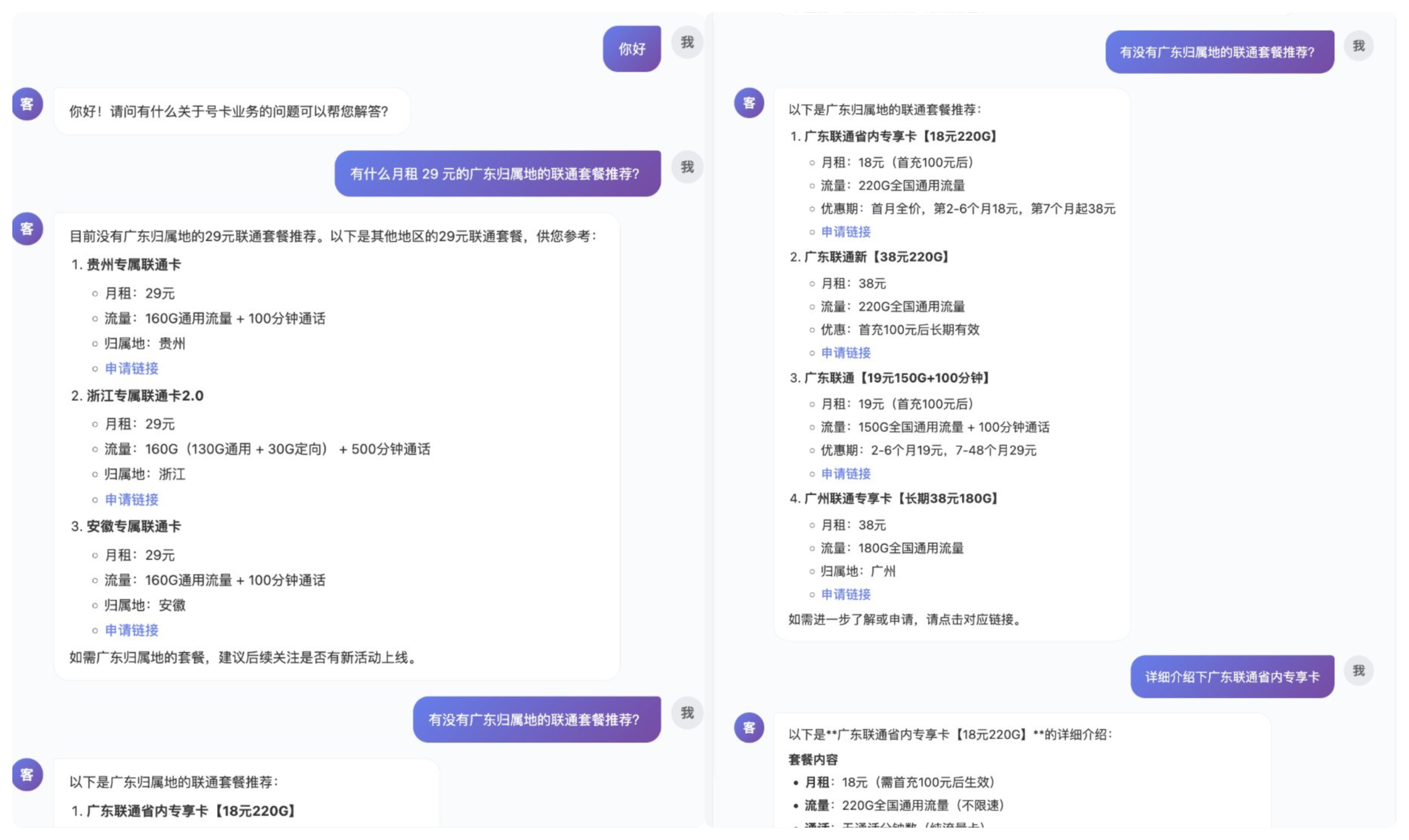

客服问答2|1000
从我自己测试以及上线后实际用户的对话来看,客服 Agent 基本可以满足需要。
接下来我阅读了 AI 实现的 Agent 代码,了解 Agent 的实现原理,毕竟一开始的目的还是「学习」。
实现细节
Agent 框架
Agent 与大模型自身最大的区别在于 Agent 可以使用工具,从而可以与外界进行交互。
现在大模型接口已经把工具调用逻辑封装好了,在调用时,直接传入工具列表,由大模型决定要不要调用工具。拿到工具结果后,再继续给到大模型,直到大模型给出最终的问题。整个过程并不复杂,下面是一个精简后的流程。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
|
import json
import os
from dotenv import load_dotenv
from openai import OpenAI
# 实际请求时使用的模型名,须与当前 base_url 后端支持的名称一致。
MODEL = "deepseek-v3.2"
# 单次「用户发一句话」之后,允许模型与工具之间最多进行多少次 API 往返。
# 例如:查天气一次 + 总结一次 = 2;若工具链更深需适当调大。
MAX_ROUNDS = 5
# ---------------------------------------------------------------------------
# 工具定义(OpenAI tools / function calling 格式)
# 模型根据 name、description、parameters 决定是否调用以及如何填参数。
# ---------------------------------------------------------------------------
QUERY_ORDER_TOOL = {
"type": "function",
"function": {
"name": "query_order",
"description": "按手机号查询用户的订单列表及状态。当用户询问订单进度、审核结果、物流、发货等问题时调用此工具。"
"仅支持使用下单手机号查询,不支持按订单号查询",
"parameters": {
"type": "object",
"properties": {
"phone": {
"type": "string",
"description": "用户下单时使用的手机号,必填。",
},
},
"required": ["phone"],
},
},
}
def query_order(phone: str) -> str:
print(phone)
return f"没有查询到相应的订单信息"
def run_tool(tool_name: str, arguments: str) -> str:
"""
执行模型选定工具:arguments 为模型生成的 JSON 字符串(对应 parameters)。
返回的字符串会写入 role=tool 的消息,模型在后续轮次中会看到该内容。
若解析失败或工具名未知,返回以「错误:」开头的说明,便于模型在对话中纠正或重试。
"""
try:
args = json.loads(arguments or "{}")
except json.JSONDecodeError as e:
return f"错误:工具参数不是合法 JSON - {e}"
if tool_name == "query_order":
phone = args.get("phone") or ""
return query_order(phone)
return f"错误:未知工具 {tool_name!r}"
def main() -> None:
# 将 .env 载入环境变量,便于本地开发不写死密钥。
load_dotenv()
api_key = os.environ.get("OPENAI_API_KEY")
base_url = os.environ.get("OPENAI_BASE_URL")
client = OpenAI(api_key=api_key, base_url=base_url)
# 对话历史:按时间顺序追加;每条为 {"role": "...", "content": "...", ...}。
# assistant 若带 tool_calls,需整条 model_dump 追加;tool 消息必须带 tool_call_id。
messages = []
tools = [QUERY_ORDER_TOOL]
user_input = input("请输入用户输入(直接回车退出): ").strip()
messages.append({"role": "user", "content": user_input})
for round_idx in range(1, MAX_ROUNDS + 1):
print(f"\n--- API 第 {round_idx}/{MAX_ROUNDS} 轮,当前消息数: {len(messages)} ---")
print(messages)
resp = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=tools,
# 由模型决定是否调用工具;若需禁止工具可改为 "none"(视服务商支持情况)。
tool_choice="auto",
)
choice = resp.choices[0]
reason = choice.finish_reason
# ---------- 分支 A:模型不再调用工具(正常结束本次用户句) ----------
if reason != "tool_calls":
content = choice.message.content
if content:
print(content)
break
# ---------- 分支 B:模型要求调用工具 ----------
# 必须先追加 assistant 消息(含 tool_calls 字段),再逐条追加 tool 回复,顺序不能乱。
messages.append(choice.message.model_dump())
for tc in choice.message.tool_calls:
tool_name = tc.function.name
tool_input = tc.function.arguments
print(f"调用工具: {tool_name}, 输入: {tool_input}")
result = run_tool(tool_name, tool_input)
messages.append(
{
"role": "tool",
"content": result,
"tool_call_id": tc.id,
}
)
if __name__ == "__main__":
main()
|
整个示例中展示了一个查询订单的工具(接口 mock 掉了)调用。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
# 订单查询工具
QUERY_ORDER_TOOL = {
"type": "function",
"function": {
"name": "query_order",
"description": "按手机号查询用户的订单列表及状态。当用户询问订单进度、审核结果、物流、发货等问题时调用此工具。"
"仅支持使用下单手机号查询,不支持按订单号查询",
"parameters": {
"type": "object",
"properties": {
"phone": {
"type": "string",
"description": "用户下单时使用的手机号,必填。",
},
},
"required": ["phone"],
},
},
}
# 调用大模型接口
resp = client.chat.completions.create(
model=MODEL,
messages=messages,
tools=[QUERY_ORDER_TOOL],
# 由模型决定是否调用工具;若需禁止工具可改为 "none"(视服务商支持情况)。
tool_choice="auto",
)
|
大模型基于当前的问题以及工具的说明决定是否调用工具,如果调用工具,那么在响应的 finish_reason 字段将会是 tool_call,同时响应里会带上工具的「工具名」以及「参数」。在调用工具并拿到结果后,以 tool 消息的形式写入上下文,由大模型进行下一轮的回复。
下面是本地测试的一个示例。
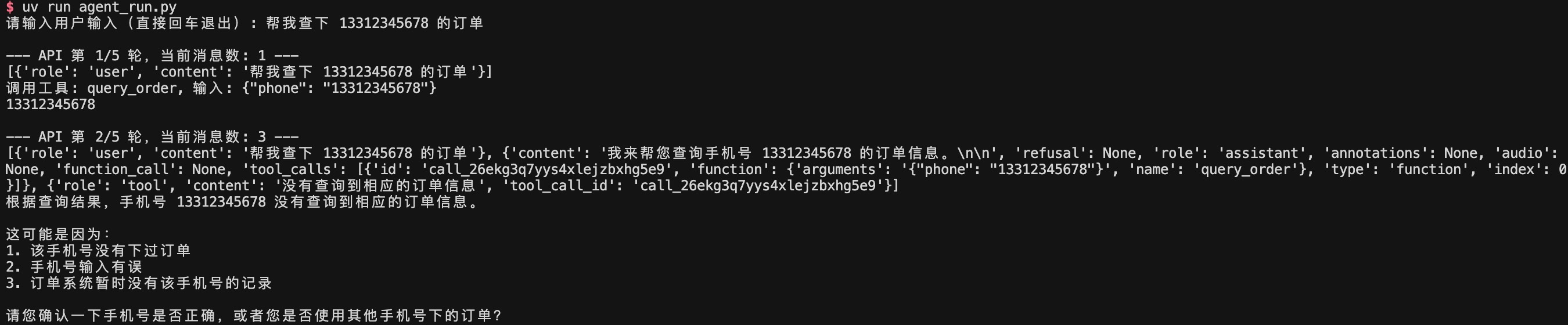
在整个客服 Agent 中,共有订单查询和知识库检索这两个工具。
知识库
为了让大模型回答用户某个套餐的信息,需要借助知识库,在用户询问套餐信息时,大模型先从知识库中获取该套餐的信息,经过组织,再对用户进行答复。
查询知识库之前,需要先生成知识库。知识库的内容分为两类。
- 每个套餐的详细信息,包括优惠信息,归属地,申请限制条件等等。由于网站基于 hexo,因此每个套餐的详细信息都对应着一个 markdown 文本文件。
- 除了套餐之外的常识信息,例如基础的术语说明、注意事项和激活、注销等常见问题。这类信息我则单独整理了一个 markdown 文件。
接下来,为了能够支持语义检索,需要对这些知识进行切块并进行 embedding。
一开始想着直接在服务器本地对文本进行 embedding 操作,但询问大模型后,服务器的配置太低扛不住,遂放弃。一番查找后,发现硅基流动免费提供 bge-m3 嵌入模型,果断采用。分块以及进行嵌入的逻辑均由大模型帮我实现,其中嵌入后的向量数据存储在本地的 Chroma DB 中。
在一番测试后,我对这两种知识采用了不同的分块逻辑。
对于号卡套餐来说, 每个套餐的 markdown 作为完整的一个分块,这样在大模型检索到后,可以获取该套餐的所有信息,不会存在信息被分割在不同分块中的问题。
而对于常识信息,我则以类似 QA 的形式进行组织,在分块时,将每个 QA 的内容作为一个分块,这样大模型在检索时也会得到最为合适的 QA 内容。
为了在给用户推荐套餐时可以让用户进行条件筛选,在录入知识库时,我还把每个套餐的元信息(运营商、资费等)入到了 Chroma DB 中,这样可以让大模型基于这些元信息直接筛选套餐。
小结
功能上线后,累计已经处理了 30+ 次用户问答,每次问答记录都会推送到我手机上,整体来看,这个客服 Agent 基本可以满足要求。我得到解放的同时,也大概了解了 Agent 的原理,真是一举两得。